

Finding the Mode of a Data Set

Write the numbers in your data set. Modes are typically taken from sets of statistical data points or lists of numerical values. Thus, to find a mode, you'll need a data set to find it for. It's difficult to do mode calculations mentally for all but the smallest of datasets, so, in most cases, it's wise to begin by writing (or typing) your data set out. If you're working with paper and a pencil, simply writing the values of your data set in sequence will suffice, while if you're using a computer, you may want to use a spreadsheet program to streamline the process. The process of finding a data set's mode is easier to understand by following along with an example problem. In this section, let's use this set of values for the purposes of our example: {18, 21, 11, 21, 15, 19, 17, 21, 17}. In the next few steps, we'll find the mode of this set.

Order the numbers from smallest to largest. Next, it's often a wise idea to sort the values of your data set so that they're in ascending order. Though this isn't strictly required, it makes the process of finding the mode easier because it groups identical values next to each other. For large data sets, it can be practically a necessity, as sorting through long lists of values and keeping mental tallies of how many times each number appears in the list is difficult and can lead to mistakes. If you're working with paper and a pencil, re-writing can save time in the long run. Scan the set of numbers for the lowest number and, when you find it, cross it off in the first data set and re-write it in your new data set. Repeat for the second-lowest number, third-lowest, and so on, being sure to write each number as many times as it occurs in the original data set. With a computer your options are more extensive - for instance, most spreadsheet programs will have the option to re-order lists of values from least to greatest with just a few clicks. In our example, after re-ordering, the new list of values should read: {11, 15, 17, 17, 18, 19, 21, 21, 21}.
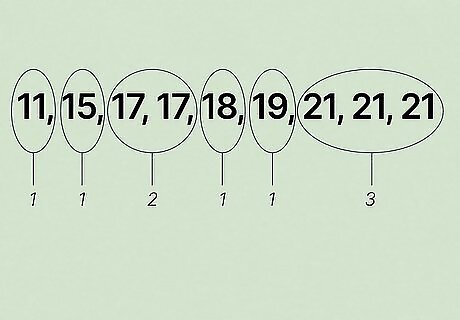
Count the number of times each number is repeated. Next, count the number of times that each number in the set appears. Look for the value that occurs most commonly in the data set. For relatively small data sets with points arranged in ascending order, this is usually a simple matter of finding the biggest "cluster" of identical values and counting the number of occurrences. If you're working with a pencil and paper, to keep track of your counts, try writing the number of times each value occurs above each cluster of identical numbers. If you're using a spreadsheet program on a computer, you can do the same thing by writing your totals in adjacent cells or, alternatively, using one of the program's options for tallying data points. In our example, ({11, 15, 17, 17, 18, 19, 21, 21, 21}),11 occurs once, 15 occurs once, 17 occurs twice, 18 occurs once, 19 occurs once, and 21 occurs three times. 21 is the most common value in this data set.
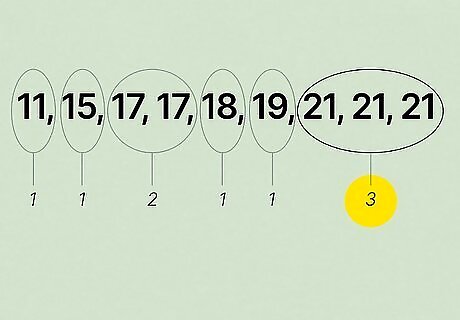
Identify the value (or values) that occur most often. When you know how many times each value occurs in your data set, find the value that occurs the greatest number of times. This is your data set's mode. Note that there can be more than one mode in a data set. If the two values are tied for being the most common values in the set, the data set can be said to be bimodal, whereas if three values are tied, the set is trimodal, and so on. In our example set, ({11, 15, 17, 17, 18, 19, 21, 21, 21}), because 21 occurs more times than any other value, 21 is the mode. If a value besides 21 had also occurred three times, (like, for instance, if there were one more 17 in the data set), 21 and this other number would both be the mode.

Don't confuse a data set's mode with its mean or median. Three statistical concepts that are often discussed together are means, medians, and modes. Because these concepts all have similar-sounding names and because, for a single data set, a single value can sometimes be more than one of these things, it's easy to confuse them. However, regardless of whether or not the data set's mode is also it's median or mean, it's important to understand that these three concepts are entirely independent of each other. See below: A data set's mean is its average. To find the mean, add up all of the values in the data set, then divide by the number of values in the set. For instance, for our example data set ({11, 15, 17, 17, 18, 19, 21, 21, 21}), the mean would be 11 + 15 + 17 + 17 + 18 + 19 + 21 + 21 + 21 = 160/9 = 17.78. Note that we divided the sum of the values by 9 because there are a total of 9 values in the data set.Find the Mode of a Set of Numbers Step 5Bullet1 Version 2.jpg A data set's median is the "middle number" separating the lower and higher values of a data set into two equal halves. For instance, in our example data set, ({11, 15, 17, 17, 18, 19, 21, 21, 21}) 18 is the median because it is the middle number - there are exactly four numbers higher than it and four numbers lower than it. Note that if there are an even number of values in the data set, there is no single median. In these cases, the median is usually taken to be the mean of the two middle numbers.Find the Mode of a Set of Numbers Step 5Bullet2 Version 2.jpg
Finding the Mode in Special Cases
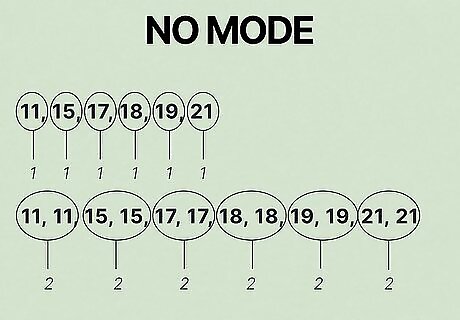
Recognize that no mode exists for data sets in which every value occurs the same number of times. If the values in a given set all occur the same number of times, the data set has no mode because no number is any more common than any other. For instance, data sets in which every value occurs once have no mode. The same is true for data sets in which every value occurs twice, three times, and so on. If we change our example data set to {11, 15, 17, 18, 19, 21} so that each value occurs only once, the data set now has no mode. The same is true if we change the data set so that each value occurs twice: {11, 11, 15, 15, 17, 17, 18, 18, 19, 19, 21, 21}.
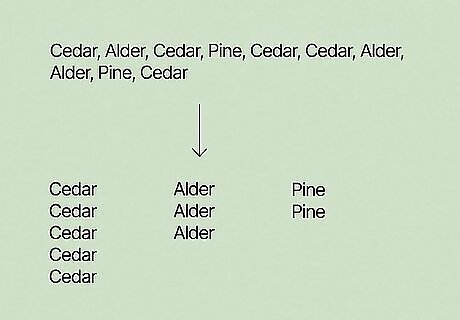
Recognize that modes for non-numerical data sets can be found in the same way as for numerical data sets. Generally, most data sets are quantitative - they deal with data in the form of numbers. However, some data sets deal with data that is not expressed in the form of numbers. In these cases, the "mode" can be said to be the single value that occurs the most in the data set, much as it is for numerical data sets. In these cases, it may be possible to find the mode while being impossible to find a meaningful median or mean for the data set. For example, let's say that a biological survey determines the species of each tree in a small local part. The data set for the types of trees in the park is {Cedar, Alder, Cedar, Pine, Cedar, Cedar, Alder, Alder, Pine, Cedar}. This type of data set is called a nominal data set because the data points are distinguished only by their names. In this case, the mode of the data set is Cedar because it occurs the most often (five times as opposed to three for Alder and two for Pine). Note that, for the example data set above, it's impossible to calculate a mean or median because the data points have no numerical value.
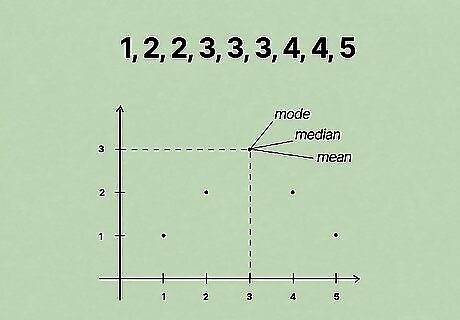
Recognize that for unimodal symmetric distributions, the mode, mean, and median coincide. As noted above, it's possible for the mode, median, and/or mean to overlap in certain cases. In special, select cases where the density function of the data set forms a perfectly symmetrical curve with one mode (for example, the Gaussian or "Bell-Shaped" Curve), the mode, mean, and median will all be the same value. Because a distribution function graphs the relative occurrence of data points, the mode will naturally be in the exact middle of a symmetrical distribution curve, as this is the highest point on the graph and corresponds to the most common value. Because the data set is symmetrical, this point on the graph will correspond with the median - the middle value in the data set - and the mean - the average of the data set. For example, let's consider the data set {1, 2, 2, 3, 3, 3, 4, 4, 5}. If we were to graph the distribution of this data set, we'd get a symmetrical curve that reaches a height of 3 at x = 3 and tapers off to a height of 1 at x = 1 and x = 5. Because 3 is the most common value, it is the mode. Because the central 3 in the data set has 4 values on either side of it, 3 is also the median. Finally, the average of the data set works out to 1 + 2 + 2 + 3 + 3 + 3 + 4 + 4 + 5 = 27/9 = 3, meaning that 3 is also the mean. The exception to this rule is for symmetrical data sets with more than one mode - in this case, because there can be only one median and mean for the data set, both modes will not coincide with these other points.


















Comments
0 comment